お問い合わせください
場所をめぐる適切なインサイトの発見が大きな成功につながります -
Pinnacle
Azira Platform を活用すれば、店舗、レストラン、建物、都市など、
場所や競合他社のインサイトをより深く理解し、活用できます。
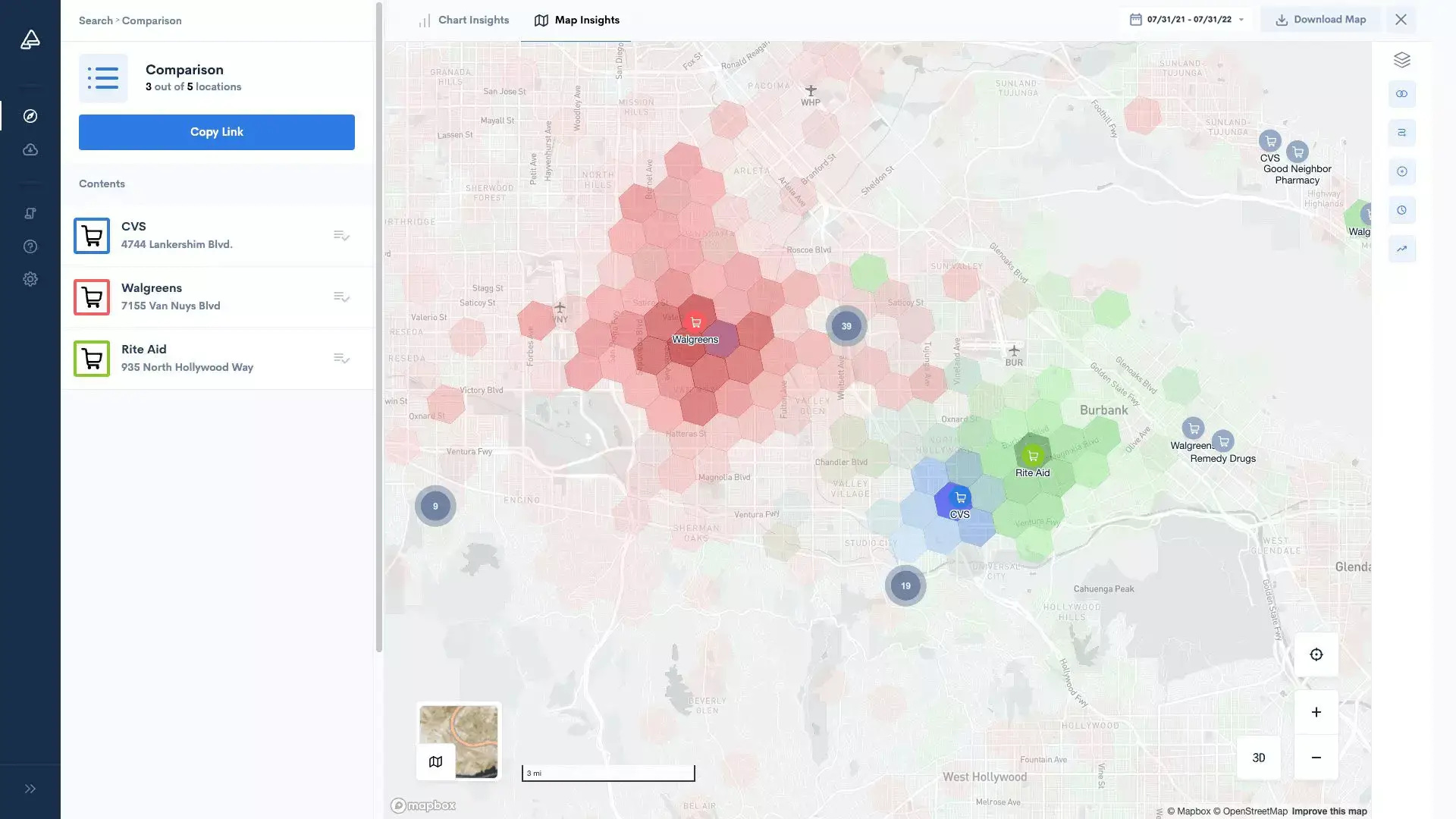
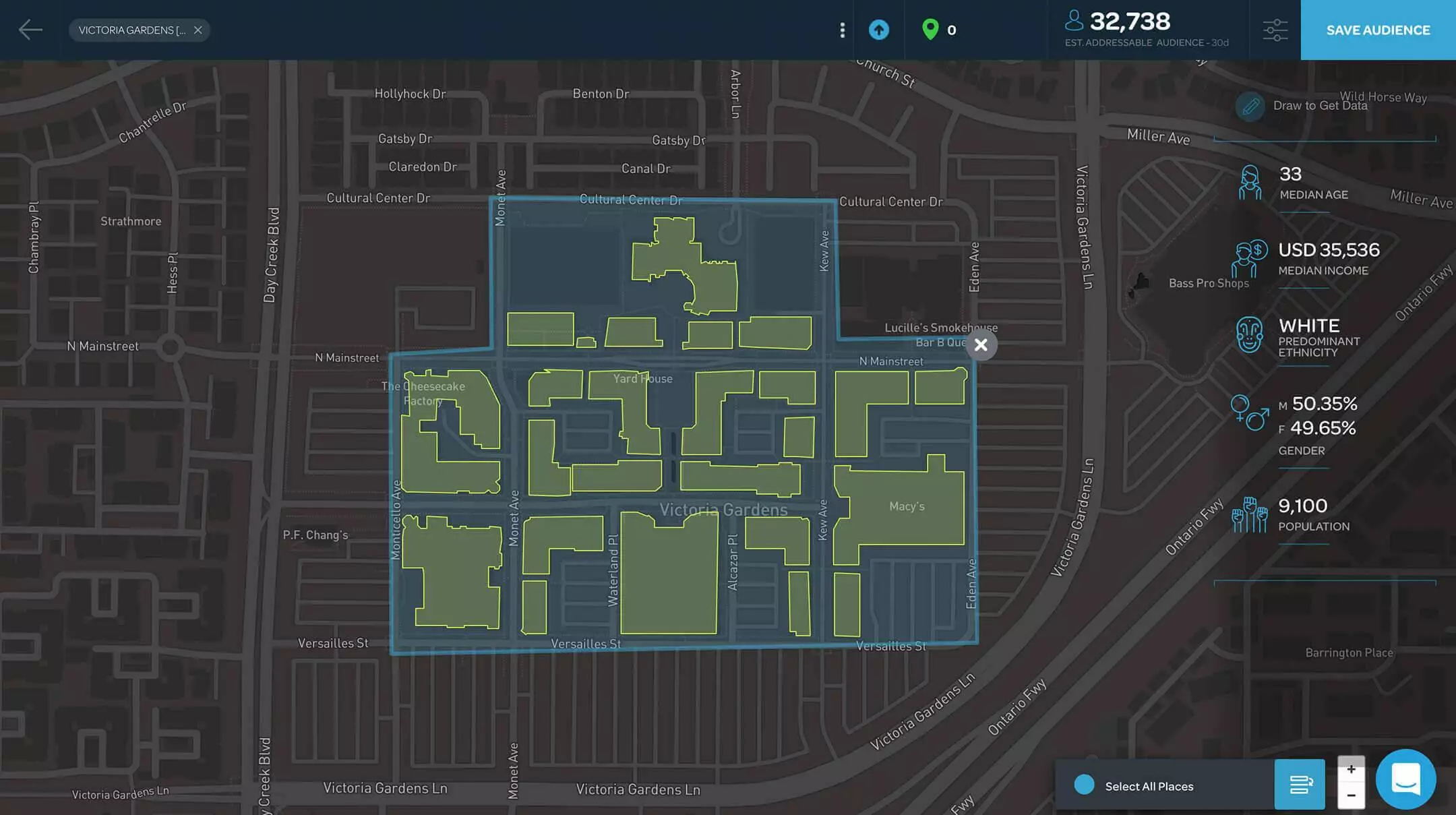
場所の発見
世界各国の場所をめぐるかつてないインサイト
事前処理データ
一瞬で過去のトレンドにアクセス
競争力のあるインサイト
訪問トレンドを活用して競合に勝つ
カスタム分析
旅行・観光、不動産、小売業界向けソリューション
世界初のAIオーディエンス・アシスタントによるシンプルなマーケティング
- Allspark
Azira Platform を活用すれば、関連性の高いオーダーメイドのオーディエンスをその場でキュレートし、主要プラットフォームで分析・アクティベーションできます。
マーケティングROI
多様なチャネルでマーケティン
グ費のROIを最大化
顧客獲得
客足を拡大して
顧客獲得を強化
顧客の維持
カスタマーロイヤリティを強化して解約率を軽減
ライフタイムバリュー
顧客内シェアを拡大してLTVを
最大化
Azira の強み
最大規模
世界44カ国16億
人のユーザー
プライバシー
バイデザイン
GDPRと
CCPAに準拠
精度の高いデータ
業界ベンチマークを超える水準
最新鋭の
テクノロジー
高度AI/ML
クラウドインフラ
グローバルな
事業展開
各国サポート
チーム
履歴データ
過去4年分の分析